이전 포스팅에서 기본적인 axis(축)을 기준으로 한 수학적 연산에 대해 알아보았다. np.sum(), np.mean() 정도로 괴랄한 수학 공식들을 코드로 작성키에 부족하다.
좀 더 업그레이드된 수치 계산 메소드들을 알아보도록 하자
1. np.cumsum()
np.cumsum()은 "Cumulative Sum"을 리턴하는 메소드이다.
np.cumsum()의 동작 과정을 코드로 이해해보도록 하자
import numpy as np
a_n = 5
a = np.arange(a_n) # [0 1 2 3 4]
cumsum_np = np.cumsum(a)
cumsum_py = []
for i in range(a_n):
tmp_arr = a[:i+1]
sum = 0
for j in range(i+1): # np.sum(tmp_arr)
sum += tmp_arr[j]
cumsum_py.append(sum)
print(cumsum_np)
# [ 0 1 3 6 10]
print(cumsum_py)
# [0, 1, 3, 6, 10]np.cumsum()의 동작과정을 for문을 이용해 요소마다의 동작 과정을 표현해 보았다.
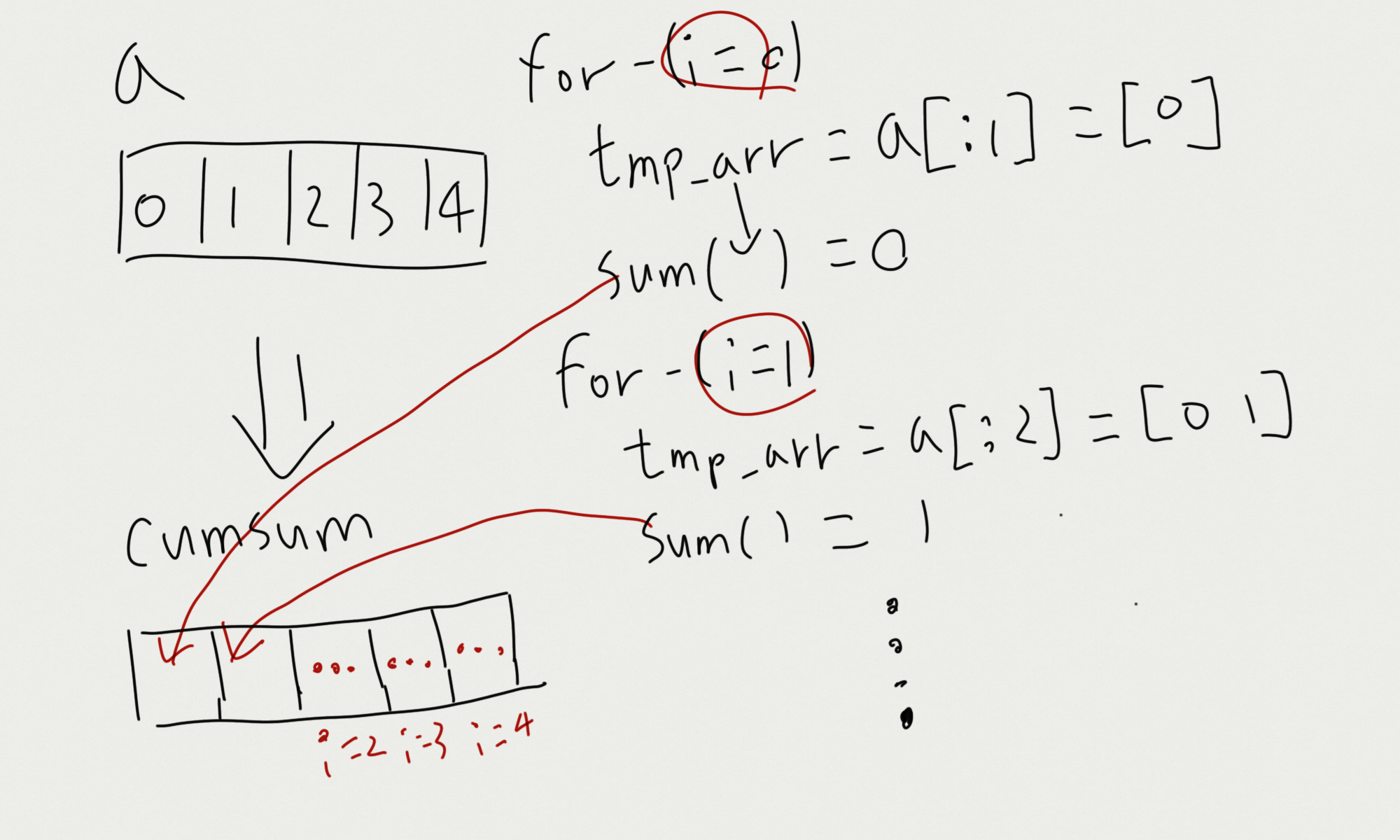
그림으로 표현해보면, cumsum 객체의 특정 index 요소들은 a의 처음부터 ~ 특정 index의 요소까지의 누적합(np.sum())이 담긴다.
이러한 맥락을 이해하고, 다차원 배열의 경우까지 확인해봤다.
import numpy as np
a = np.arange(5)
print(a) # [0 1 2 3 4]
cumsum = np.cumsum(a)
print(cumsum) # [ 0 1 3 6 10]
a = np.arange(3*3).reshape((3,3))
print(a)
# [[0 1 2]
# [3 4 5]
# [6 7 8]]
cumsum = np.cumsum(a)
print(cumsum)
# [ 0 1 3 6 10 15 21 28 36]
a = np.arange(2*3*4).reshape((2,3,4))
print(a)
# [[[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
# [[12 13 14 15]
# [16 17 18 19]
# [20 21 22 23]]]
cumsum = np.cumsum(a)
print(cumsum)
# [ 0 1 3 6 10 15 21 28 36
# 45 55 66 78 91 105 120 136 153
# 171 190 210 231 253 276]코드와 결과를 살펴보니 np.cumsum()은 다차원 배열일 경우에도, 1차원 배열(벡터)의 형태로 표현된다.
axis 속성을 추가하면 결과의 shape이 달라질까?
확인해보자.
import numpy as np
a = np.arange(3*3).reshape((3, 3))
print(a)
# [[0 1 2]
# [3 4 5]
# [6 7 8]]
cumsum_axis_0 = np.cumsum(a, axis=0)
print(cumsum_axis_0)
# [[ 0 1 2]
# [ 3 5 7]
# [ 9 12 15]]
cumsum_axis_1 = np.cumsum(a, axis=1)
print(cumsum_axis_1)
# [[ 0 1 3]
# [ 3 7 12]
# [ 6 13 21]]axis 속성에 따라 값이 달라진다. 어떤 식으로 계산되는지, 그림을 통해 이해해보자.

그림을 통해 이해한 것을 정리해보겠다.
axis 속성을 활용하면, 설정한 축을 기준으로 배열을 쪼개고, 그 쪼개진 배열들끼리 다시 np.cumsum()을 진행하는 식으로 연산이 진행된다.
처음 볼 때는 복잡해 보이지만, 값과 연산 순서를 생각하며 바라보면, 이해가 간다.
2. np.prod()
np.prod()는 "product(곱)"을 수행하는 메소드이다.
import numpy as np
a = np.arange(1, 6) # [1 2 3 4 5]
prod_np = np.prod(a)
prod_py = 1
for i in range(6-1):
prod_py *= a[i]
print(prod_np) # 120
print(prod_py) # 120내부 연산과정을 생각해보면 위 코드의 for문을 확인해보자.
다차원 배열의 경우도 코드로 확인해보자
import numpy as np
a = np.arange(1, 5+1)
print(a) # [1 2 3 4 5]
product = np.product(a)
print(product) # 120
a = np.arange(1, 3*3+1).reshape((3,3))
print(a)
# [[1 2 3]
# [4 5 6]
# [7 8 9]]
product = np.product(a)
print(product) # 362880
a = np.arange(1, 2*3*4+1).reshape((2,3,4))
print(a)
# [[[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
# [[13 14 15 16]
# [17 18 19 20]
# [21 22 23 24]]]
product = np.product(a)
print(product) # -775946240 int oversize error역시, axis 속성을 사용하지 않으니, np.prot()는 스칼라의 형태로 값이 나온다.
axis를 활용해 축을 기준으로 한 np.prod()를 진행해보자
import numpy as np
a = np.arange(1, 3*3+1).reshape((3,3))
print(a)
# [[1 2 3]
# [4 5 6]
# [7 8 9]]
prod = np.product(a)
print(prod) # 362880
prod_axis_0 = np.product(a, axis=0)
print(prod_axis_0) # [ 28 80 162]
prod_axis_1 = np.product(a, axis=1)
print(prod_axis_1) # [ 6 120 504]위 np.cumsum()을 통해 이해했던 내용처럼 np.prod()도 마찬가지로 axis(축)을 기준으로 다차원 배열을 쪼개고, 그 쪼개진 배열끼리 np.prod()를 진행하고, 그 값이 요소로서 저장된다.
그림은 내가 못 그려서 패스하도록 하겠다..........
3. np.diff()
np.diff()는 (Numpy 개발 문서에 따르면) "주어진 축을 따라 n번째 이산 차이를 계산한다.(Calculate the n-th discrete difference along the given axis)"라고 정의할 수 있다.
out[i] = a[i] - a[i-1]
위의 코드와 같이 연산이 진행된다.
import numpy as np
a = np.random.randint(0, 10, (5,))
print(a, a.shape) # [3 0 1 5 8] (5,)
diff = np.diff(a)
print(diff, diff.shape) # [-3 1 4 3] (4,)코드를 바라보면 out[i] = a[i+1] - a[i]의 형태로 연산이 진행돼 diff에 담긴다.
그림으로 그려보자면,
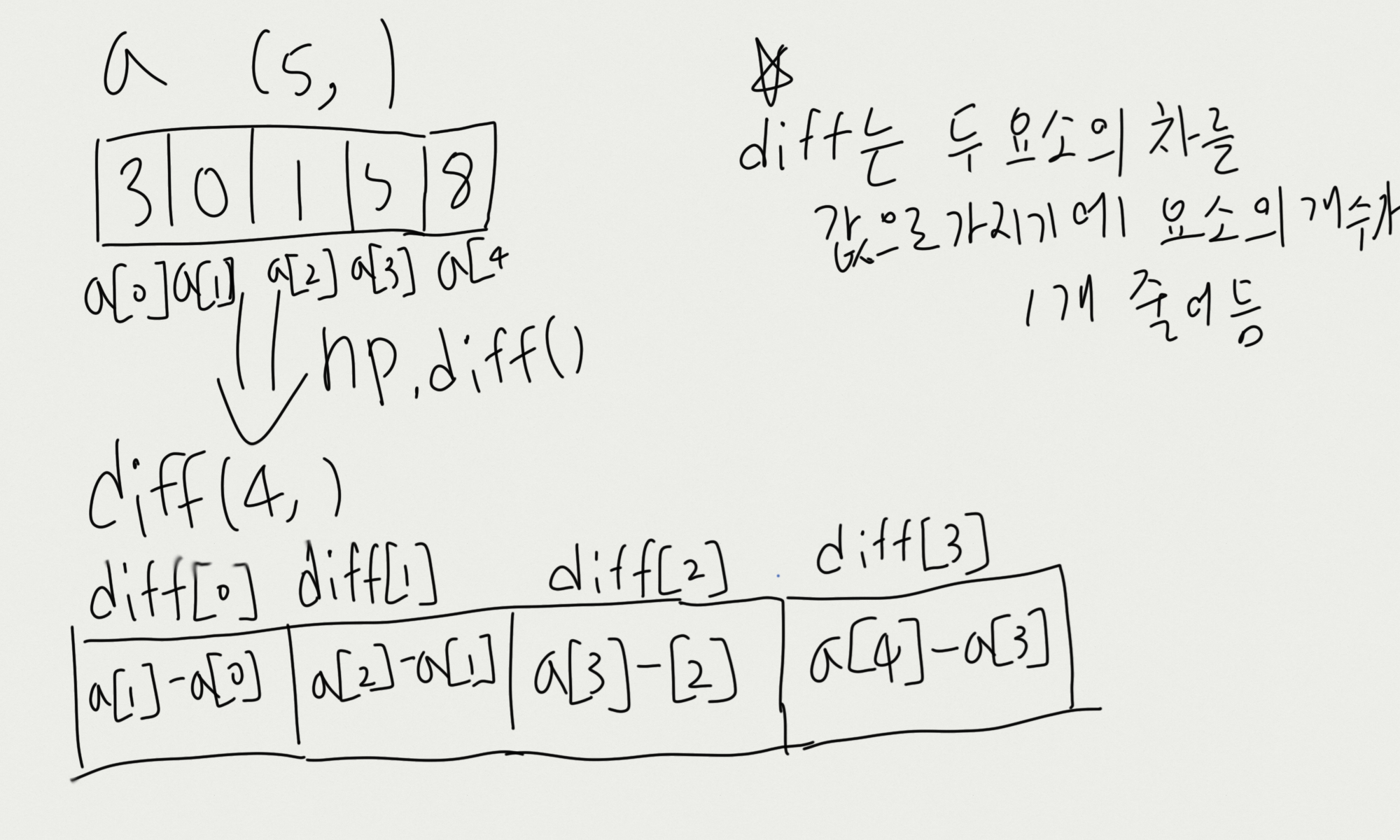
이런 식의 연산이라면, 다차원 배열의 경우에도 벡터의 형태로 리턴될 것이다.
그럼 axis 속성을 설정한 경우를 확인해보자
import numpy as np
a = np.random.randint(0, 10, (3,3))
print(a)
# [[5 0 9]
# [0 3 4]
# [9 3 9]]
diff_axis_0 = np.diff(a, axis=0)
print(diff_axis_0) # (2, 3)
# [[-5 3 -5]
# [ 9 0 5]]
diff_axis_1 = np.diff(a, axis=1)
print(diff_axis_1) # (3, 2)
# [[-5 9]
# [ 3 1]
# [-6 6]]코드의 결과를 통해 바라보면 떠오르는 말은 "축이 사라진다, 줄어든다!"는 개념을 떠올리면 좋을 것 같다.
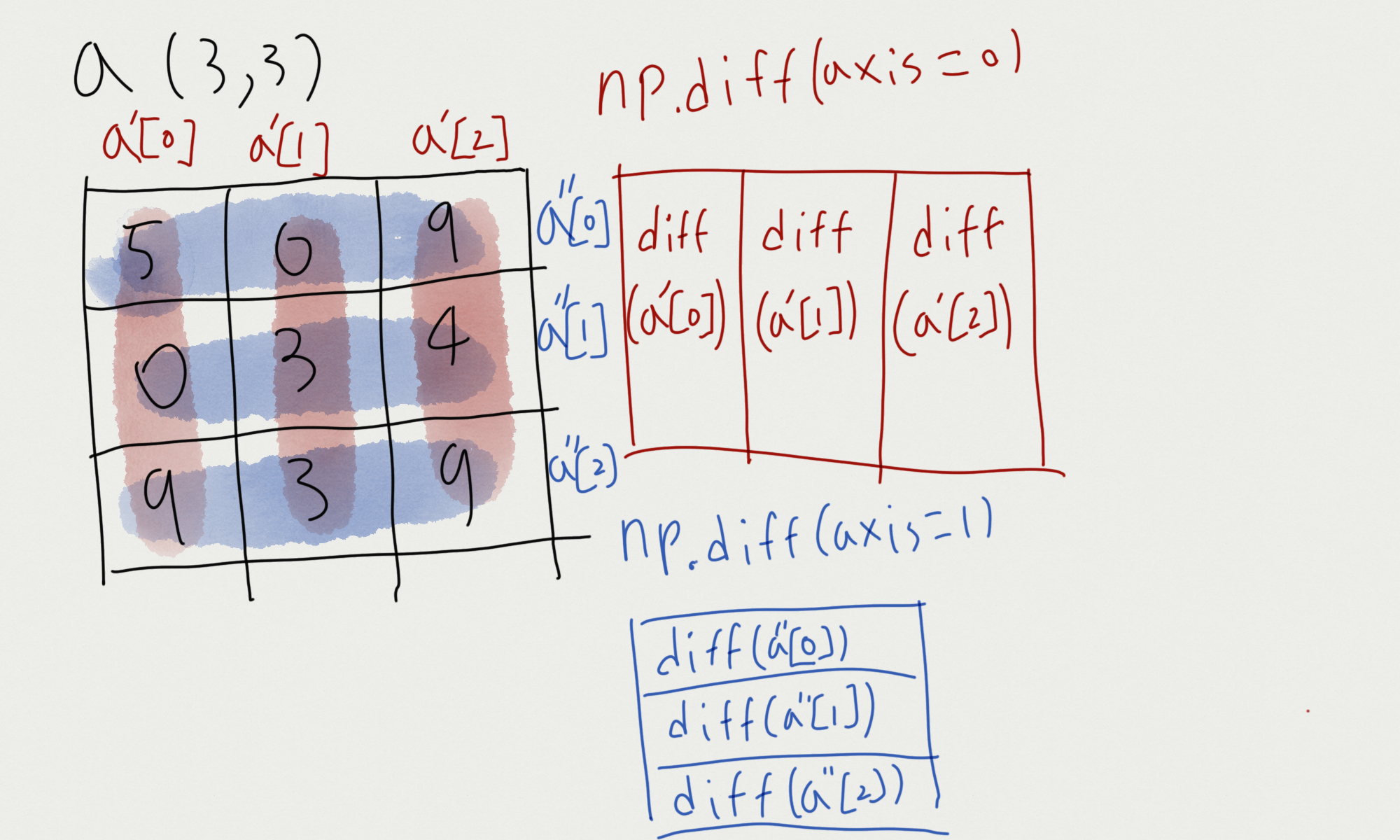
축을 기준으로 쪼개진 배열에 np.diff()를 진행하는 것이다. np.diff()는 요소를 하나 줄어들기에,
np.diff(axis=0).shape = (2, 3)
np.diff(axis=1).shape = (2, 3)
으로 변환되는 것이다.
3차원 배열의 경우를 살펴보며, np.diff()에 대한 정리를 마무리하겠다.
import numpy as np
a = np.random.randint(0, 10, (2,3,4))
print(a)
# [[[9 9 4 5]
# [0 2 9 3]
# [8 8 6 3]]
# [[7 7 5 6]
# [7 4 6 3]
# [9 6 2 6]]]
diff_axis_0 = np.diff(a, axis=0)
print(diff_axis_0)
# [[[-2 -2 1 1]
# [ 7 2 -3 0]
# [ 1 -2 -4 3]]]
diff_axis_1 = np.diff(a, axis=1)
print(diff_axis_1)
# [[[-9 -7 5 -2]
# [ 8 6 -3 0]]
# [[ 0 -3 1 -3]
# [ 2 2 -4 3]]]
diff_axis_2 = np.diff(a, axis=2)
print(diff_axis_2)
# [[[ 0 -5 1]
# [ 2 7 -6]
# [ 0 -2 -3]]
# [[ 0 -2 1]
# [-3 2 -3]
# [-3 -4 4]]]
4. np.mean(), np.median()
np.mean()은 이전 포스팅에서 알아보았으나, 평균 비슷한 것을 구하는 np.median()가 있고,
이 둘의 차이를 비교하는 것이 서로를 이해하는데 도움이 될 것이다.
np.median()은 "중앙값, 중위수"를 리턴하는 메소드이다. "평균"과 "중앙값"은 수학적으로 다른 개념이다.
배열의 평균(mean) = 요소들의 전체합 / 요소들의 개수
배열의 중앙값(median) = 가장 중앙에 위치하는 값
코드를 통해 바라보자
import numpy as np
x = np.arange(10)
print(x) # [0 1 2 3 4 5 6 7 8 9]
mean = np.mean(x)
median = np.median(x)
print(mean) # 4.5
print(median) # 4.5
# 원소의 개수 : 홀수
x = np.random.randint(1, 11, (5, ))
print(x) # [2 9 8 4 1]
print(np.sort(x)) # [1 2 4 8 9]
mean = np.mean(x)
median = np.median(x)
print(mean) # 4.8
print(median) # 4.0
# 원소의 개수 : 짝수
x = np.random.randint(1, 11, (8, ))
print(x) # [ 5 2 6 9 9 2 10 9]
print(np.sort(x)) # [ 2 2 5 6 9 9 9 10]
mean = np.mean(x)
median = np.median(x)
print(mean) # 6.5
print(median) # 7.5위의 코드를 보면 평균과 중앙값의 차이를 볼 수 있다.
일반적으로 평균과 중앙값이 비슷할 수 있지만, 실제로 구해지는 방식은 다르다.
원소의 개수가 홀수일 때, 평균과 중앙값을 구하면,
평균 : 요소들의 전체합 / 요소들의 개수
중앙값 : 오름차순 정렬된 원소들, 그중 가장 가운데 값
원소의 개수가 짝수일 때, 평균과 중앙값을 구하면,
평균 : 요소들의 전체합 / 요소들의 개수
중앙값 : 오름차순 정렬된 원소들, 그중 가장 가운데인 두 개의 원소의 평균
위와 같은 방식으로 정리할 수 있다.
이러한 차이는 중요한 의미를 가진다. 한마디로 표현하면, "튀는 값을 잡아준다"
코드를 통해 바라보자
import numpy as np
x = np.random.randint(1, 10, (100, ))
mean = np.mean(x)
median = np.median(x)
print(mean) # 5.05
print(median) # 5.0
# 튀는 값 1000 추가
x = np.append(x, 1000)
mean = np.mean(x)
median = np.median(x)
print(mean) # 14.900990099009901
print(median) # 5.0
위 코드를 살펴보면, median의 중요성을 알 수 있다.
mean(평균)의 경우에는 "원소의 총합/원소의 개수"임으로, 튀는 값에 따라 값이 크게 변한다.
median(중앙값)의 경우에는 "가장 가운데 값"임으로, 튀는 값에 따라 값이 변하지 않는다.
이러한 맥락에서 보면, 상황에 따라 중앙값을 사용하는 것이 더 안전하게 평균과 같은 가운데 값을 구할 수 있다.
5. np.var(), np.std()
median과 함께 확률과 통계 등에서 활용되는 개념들이 나왔다.
np.var()는 "분산"을 리턴하는 메소드이다.
np.std()는 "표준편차"를 리턴하는 메소드이다.
사실 분산, 표준편차를 다 까먹었어서 관련해서 이전에 포스팅한 적이 있다.
https://doyou-study.tistory.com/41?category=960400
[수학] 정규분포란
Numpy.random.normal를 공부하다 메소드 구현은 가능하나, 관련한 설명을 이해못하겠어서 직접 공부해보려한다. 정규분포를 검색해보면 이런 그림이 등장한다. 어디서 본적은 있는거같은데 정확하게
doyou-study.tistory.com
분산, 표준편차는 어떤 방식으로 나타나는지, 코드를 통해 살펴보자
import numpy as np
# loc(평균): 0, scale(표준편차): 3인 정규분포에서
# 난수 100개 생성
data = np.random.normal(loc=10,
scale=5,
size=(100, ))
std = data.std()
# 표준편차 구하는 과정
x = np.abs(data - np.mean(data)) ** 2
std_ = np.sqrt(np.mean(x))
print(round(std,2), round(std_,2)) # 소수점 2자리까지 출력
# 4.46 4.46
var = data.var()
var_ = std ** 2
print(round(var,2), round(var_,2))
# 19.85 19.85data.std()는 표준편차를 리턴하는 메소드이다.
표준편차, 분산을 구하는 공식은 아래와 같고, 위의 코드에 표현했다.
$$ \sigma \ = \ \sqrt{\frac{\Sigma(x_i - \mu)^2}{N}} $$
$$ \sigma \ = 표준편차 \ ,\ N \ = 요소의 개수 \ ,\ x_i = 요소의 값 \ ,\ \mu \ = 요소들의 평균\ $$
$$ v \ = \ \frac{\Sigma(x_i - \mu)^2}{N} $$
$$ v \ = \ 분산 \ ,\ N \ = 요소의 개수 \ ,\ x_i = 요소의 값 \ ,\ \mu \ = 요소들의 평균\ $$
뭔가 먼저인지를 모르겠지만ㅋㅋ 분산 공식은 위와 같다.
결국, 표준편차^2 = 분산, √분산 = 표준편차이다.
다양한 방식으로 활용될 메소드이니 꼭 기억하도록 하자
6. np.max(), np.amax(), np.maximum(), np.min(), np.amin(), np.minimum()
마지막, 최대값과 최소값을 리턴하는 메소드이다. 다 같은 기능을 수행하는데, 왜 여러 개인 걸까? 공부해보자.
먼저 np.max(), np.amax(), np.maximum()에 대해 알아보자
import numpy as np
a = np.random.randint(0, 5, (10, ))
print(a)
# [3 2 2 1 4 0 4 2 3 1]
max = np.max(a)
print(max) # 4
amax = np.amax(a)
print(amax) # 4
# maximum = np.maximum(a)
# print(maximum) # error need 2 args
a = np.random.randint(0, 5, (10, ))
b = np.random.randint(0, 5, (10, ))
print(a)
print(b)
# [1 3 4 0 3 3 0 3 2 0]
# [4 4 3 1 0 3 1 3 0 4]
# max = np.max(a, b)
# print(max) # error
# amax = np.amax(a, b)
# print(amax) # error
maximum = np.maximum(a, b)
print(maximum)
# [4 4 4 1 3 3 1 3 2 4]먼저 np.max()와 np.amax()는 동일한 기능을 수행한다. 하나의 배열에서 가장 큰 요소를 리턴한다.
max의 별칭으로서 amax()를 사용한다고 이해하자. np.max() deprecated이슈가 있다고 하는데, 잘은 모르겠다.
np.max()와 np.maximum()의 차이
- np.max() : 하나의 배열에서 가장 큰 값 리턴
- np.maximum() : 두 개 이상의 배열을 비교해 동일한 index에서 더 큰 값 리턴
np.min(), np.amin(), np.minimum() 역시, 살펴보자
import numpy as np
a = np.random.randint(0, 5, (10, ))
print(a)
# [2 3 2 2 3 2 1 3 4 1]
min = np.min(a)
print(min) # 1
amin = np.amin(a)
print(amin) # 1
# minimum = np.minimum(a)
# print(minimum) # error need 2 args
a = np.random.randint(0, 5, (10, ))
b = np.random.randint(0, 5, (10, ))
print(a)
print(b)
# [0 1 4 3 0 3 3 0 3 1]
# [1 1 2 1 0 2 3 4 0 4]
# min = np.min(a, b)
# print(min) # error
# amin = np.amin(a, b)
# print(amin) # error
minimum = np.minimum(a, b)
print(minimum)
# [0 1 2 1 0 2 3 0 0 1]
이 정도로 이해하면 좋겠다. 아참, max(), min()은 axis 속성을 동일하게 적용받는다는 걸 확인해보며, 포스팅을 마무리하겠다.
import numpy as np
a = np.random.randint(0, 10, (3, 3))
print(a)
# [[8 1 0]
# [4 2 2]
# [6 1 2]]
max_axis_0 = np.max(a, axis=0)
max_axis_1 = np.max(a, axis=1)
print(max_axis_0)
# [8 2 2]
print(max_axis_1)
# [8 4 6]
min_axis_0 = np.min(a, axis=0)
min_axis_1 = np.min(a, axis=1)
print(min_axis_0)
# [4 1 0]
print(min_axis_1)
# [0 2 1]
a = np.random.randint(0, 10, (2, 3, 4))
print(a)
# [[[2 8 9 3]
# [9 8 7 9]
# [0 5 7 7]]
# [[4 5 4 8]
# [2 8 8 2]
# [4 5 7 4]]]
max_axis_0 = np.max(a, axis=0)
max_axis_1 = np.max(a, axis=1)
max_axis_2 = np.max(a, axis=2)
print(max_axis_0)
# [[4 8 9 8]
# [9 8 8 9]
# [4 5 7 7]]
print(max_axis_1)
# [[9 8 9 9]
# [4 8 8 8]]
print(max_axis_2)
# [[9 9 7]
# [8 8 7]]
min_axis_0 = np.min(a, axis=0)
min_axis_1 = np.min(a, axis=1)
min_axis_2 = np.min(a, axis=2)
print(min_axis_0)
# [[2 5 4 3]
# [2 8 7 2]
# [0 5 7 4]]
print(min_axis_1)
# [[0 5 7 3]
# [2 5 4 2]]
print(min_axis_2)
# [[2 7 0]
# [4 2 4]]
https://numpy.org/doc/stable/reference/generated/numpy.diff.html
numpy.diff — NumPy v1.21 Manual
numpy.diff numpy.diff(a, n=1, axis=-1, prepend= , append= )[source] Calculate the n-th discrete difference along the given axis. The first difference is given by out[i] = a[i+1] - a[i] along the given axis, higher differences are calculated by using diff r
numpy.org
https://numpy.org/doc/stable/reference/generated/numpy.std.html
numpy.std — NumPy v1.21 Manual
numpy.std numpy.std(a, axis=None, dtype=None, out=None, ddof=0, keepdims= , *, where= )[source] Compute the standard deviation along the specified axis. Returns the standard deviation, a measure of the spread of a distribution, of the array elements. The s
numpy.org
https://stackoverflow.com/questions/33569668/numpy-max-vs-amax-vs-maximum
numpy max vs amax vs maximum
numpy has three different functions which seem like they can be used for the same things --- except that numpy.maximum can only be used element-wise, while numpy.max and numpy.amax can be used on
stackoverflow.com


댓글